私もFIREしたいです
今年新NISAが始まりました。初心者はオルカン(全世界株式=オール・カントリー)がお勧めと言われています。
FIREしたいので私もこの波に乗りました。
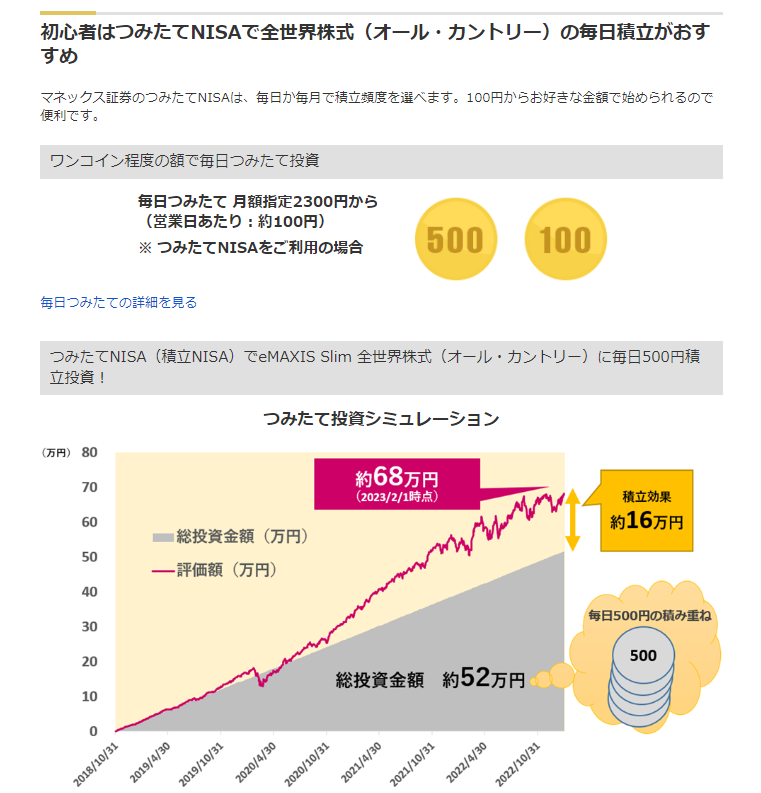
info.monex.co.jp
オルカンの積み立てNISAでは世界経済が成長することを前提に分散投資・積み立てで行うことでリスクを最小限にすることが出来ます。
新NISAの年間投資枠の範囲内であれば、利益に対する課税が免除されることもあり新NISAはやらなきゃ損、みたいな感じです。
一方で、米国株・日本株ともに歴代最高値を付けていて、このバブルがはじけたらどうなるのか?という風な考え方もあります。(オルカンはオールカントリーといいながら多くの商品は半分以上が米国株で実質的に米国株です)
そこで、過去にバブルを経験している日本株(日経平均株価)をもとにシミュレーションしてみようと考えました。
また、積み立ての仕方による利益の差がどれくらいになるのか、といった点も見てみようと思いました。
しかしながら、無料で日経平均株価のデータが取得できるのが2001年からでしたので、とりあえずこれで試してみることにします。
日経平均株価 過去のレート - Investing.com
この範囲でもミニバブルや不況、コロナショックなどが見られます。
ここで試算条件としては月三万円(毎月1日に購入)、または日割にして平日毎日961円を積み立てし、配当や手数料は考慮しないとします。
資産形成にどのような差が出るかを試算します。
試算結果
まず、月2万円で2001年から現在まで積み立てしていたと仮定した結果が以下です。

投資額が558万円で、評価額(3月22日現在)は約1610万円となりました。利益が1000万円以上、投資額に対して3倍弱になりました。
ここで、毎日購入した場合と毎月1回購入した場合では差は1%弱(最終的に約1万7千円)となりました。

積み立て周期の差については、ほぼ差がないと考えてもいいかもしれません。
特にこだわりが無ければ、投資周期はどちらでもいいかもしれませんが、差分をとってみると株価が上がる前提では安定的に毎日積み立ての方が利益が大きくなっていそうです。
さて、問題となるのは株価が下がった場合です。
最初のグラフの投資額(青線)と評価額(黄色)を比較すると、2013年1月末ごろを境にプラスとなっていることが分かります。
試算期間の始め、2001年1月5日の日経平均株価が13,867.61円、2013年1月30日の日経平均株価が11,113.95円、この間の平均株価が11,520.90円となりました。
ランダムウォークの末、20%株価が下がったときが損益分岐点となります。
これが積み立て投資の魅力ですね。
実際にはこれに配当が加わることで損益分岐点がさらに下がることになります。
さらに悲観的なパターンとして2007年12月11日のミニバブルを起点にしてみます。
この時の日経平均株価が16,044.72円です。(計算条件の統一のため、この月の12月頭からで試算します。12月3日がこの月の最初で15,628.97円です)
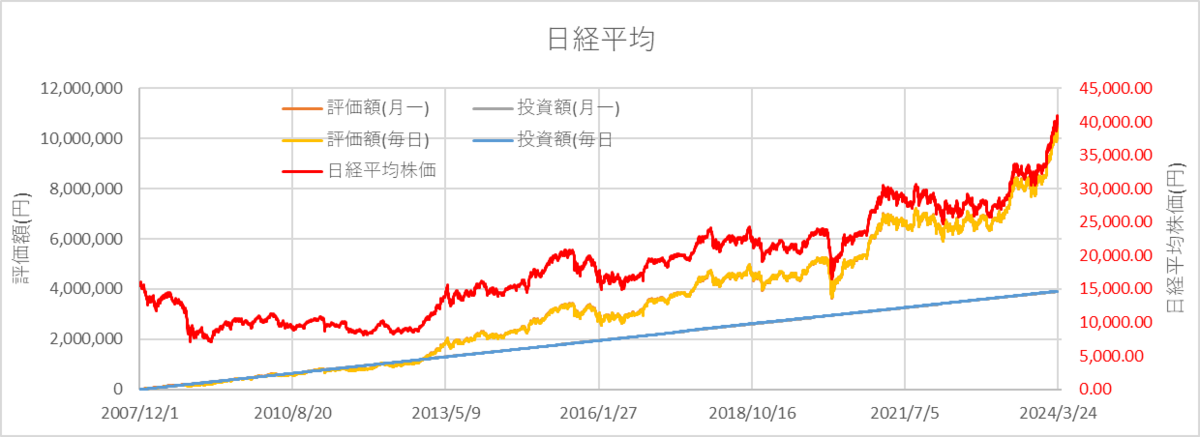
しかし、こちらも2012年12月14日の9,737.56円を境に利益となります。
こちらの月ごとと毎日の投資周期の違いでは、(グラフが常にマイナスなので)毎日の方が利益が小さくなりました。
N=2ですが、どちらの方が良いかはその時による、セオリーはない、ということになりそうです。

まとめ
積み立てNISAの試算をしました。
長期で積み立てをすれば、経済が成長する前提ではほぼ間違いなくプラスになる、ということになりそうです。
一般的に積み立ては月一でできるようになっていますが、週一や毎日で出来る証券会社もありますが、その差は小さいようです。
使っていないブログにNISA関連で考えたことを徒然なるままに書いています。いつまで続くかはわかりません。
s51517765.hatenablog.jp